![]()
|
| Regular-
|
About Regular ExpressionRegular expressions have been used since the birth of computer science with automata theory, and grew with the popularity of UNIX. 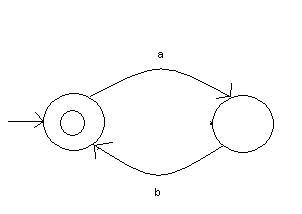
Here is an example of a very simple state machine that represents all acceptable states that have 0 or more combinations of “ab”. Here is the set of the possible acceptable outcomes: {‘’, ‘ab’, ‘abab’, ‘ababab’, …}. To represent this in short hand, a regular expression might be written as (ab)*. Regular expressions are used to represent complicated data into a simplified string. The ‘(‘ and ‘)’ are used in this case to say that the ‘ab’ are to be together, while the * represents the phrase: “zero or more”. Here are some quick references on regular expressions [Wiki]: . Matches any single character except newline. Within square brackets, the dot character matches a literal dot. For example, a.c matches "abc", etc., but [a.c] matches only "a", ".", or "c". [ ] Matches a single character that is contained within the brackets. For example, [abc] matches "a", "b", or "c". [a-z] specifies a range which matches any lowercase letter from "a" to "z". These forms can be mixed: [abcx-z] matches "a", "b", "c", "x", "y", and "z", as does [a-cx-z]. The - character is treated as a literal character if it is the last or the first character within the brackets, or if it is escaped with a backslash: [abc-], [-abc], or [a\-bc]. The [ character can be included anywhere within the brackets. To match the ] character, the easiest way is to escape it with a backslash, e.g., [\]]. Some tools allow you to avoid the backslash if the closing bracket is first in the enclosing square brackets, e.g., [][ab] matches "]", "[", "a", or "b". [^ ] Matches a single character that is not contained within the brackets. For example, [^abc] matches any character other than "a", "b", or "c". [^a-z] matches any single character that is not a lowercase letter from "a" to "z". As above, literal characters and ranges can be mixed. ^ Matches the starting position within the string. In multiline mode, it matches the starting position of any line. $ Matches the ending position of the string or the position just before a string-terminating newline. In multiline mode, it matches the ending position of any line. ( ) Defines a marked subexpression. The string matched within the parentheses can be recalled later (see the next entry, \n. A marked subexpression is also called a block or capturing group. This feature is not found in all instances of regular expressions, and in many Unix utilities including sed and vi, a backslash must precede the open and close parentheses for them to be interpreted with special meaning. \n Matches what the nth marked subexpression matched, where n is a digit from 1 to 9. This construct is theoretically irregular and was not adopted in the POSIX extended regular expression (ERE) syntax. Some tools allow referencing more than nine capturing groups. * Matches the preceding element zero or more times. For example, ab*c matches "ac", "abc", "abbbc", etc. [xyz]* matches "", "x", "y", "z", "zx", "zyx", "xyzzy", and so on. (ab)* matches "", "ab", "abab", "ababab", and so on. {m,n} Matches the preceding element at least m and not more than n times. For example, a{3,5} matches only "aaa", "aaaa", and "aaaaa". This is not found in a few, older instances of regular expressions. DownloadRequirements/Recommend:
File:Click Here to DownloadInstructions:Installation:Simply unzip the file and place the folder in the desire location. Run the [RegEx Explorer.exe] file to run the program. Running:Upload a file into the program, and then enter your regular expression into the textbox and click on the button "Parse" to view results. Sources
[Wiki] Wikimedia Foundation, Inc., “Regular expression”
http://en.wikipedia.org/wiki/Regular_expression (12:57, 18 September 2007) |